
불균형자료(Imbalanced data)의 처리
업데이트:
불균형데이터(imbalanced data)란?
-
머신러닝의 목적이 분류(Classification) 일때, 특정 클래스의 관측치가 다른 클래스에 비해 매우 낮게 나타나면 이러한 자료를 불균형자료라고 한다.
- 이러한 데이터 셋에서는, 다수의 클래스로 모두 분류할 경우 정확도(accuracy)가 높아진다
- 예를 들어, 대출 데이터에서 대출자가 연체할 확률은 2%일 경우 무조건 정상 고객으로 분류하면 98%의 정확도를 보인다.
- 하지만 이런 데이터 셋에서는 정확도(accuracy)가 높아도 데이터 갯수가 적은 클래스의 재현율(recall-rate)이 급격히 작아지는 현상이 발생 할 수 있다.
이렇게 각 클래스에 속한 데이터의 갯수의 차이에 의해 발생하는 문제들을 불균형(비대칭) 데이터 문제(imbalanced data problem)이라고 한다.
해결책
1. 과소표집(Undersampling)
다수클래스(major class)의 표본을 임의로(randomly) 학습 데이터로부터 제거. 즉, 다수의 클래스 데이터에서 일부만 사용.
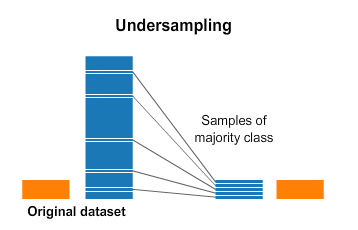
예를 들어, 0과 1이라는 클래스 데이터가 각각 100개, 5개가 있을때, 이 중 0 클래스의 데이터 중 95개를 버리고 5개만 사용합니다.
| 클래스 | 개수 |
|---|---|
| 0 | 100 |
| 1 | 5 |
에서
| 클래스 | 개수 |
|---|---|
| 0 | 5 |
| 1 | 5 |
2. 과대표집(Oversampling)
소수클래스(minor class)의 표본을 복제하여 이를 학습데이터에
소수 클래스 데이터를 증가시킴

예를 들어, 0과 1이라는 클래스 데이터가 각각 100개, 5개가 있을때, 이 중 0 클래스의 데이터를 복제해 100개를 만들어 사용합니다.
| 클래스 | 개수 |
|---|---|
| 0 | 100 |
| 1 | 5 |
에서
| 클래스 | 개수 |
|---|---|
| 0 | 100 |
| 1 | 100 |
데이터 비율을 맞추면 정밀도(precision)가 향상
- 과소표집은 표본의 수를 줄이기 때문에 모형의 정밀도를 낮추게 됩니다.
따라서, 일반적으로 과소표집보다는 과대표집이 통계적으로 유용합니다.
과대표집의 대표적인 방법
1) SMOTE
Synthetic Minority Oversampling Technique, 합성소수표집법
- 소수클래스에 속한 i번째 관측치의 특성변수 $\mathbf{x_i}$ 에 대해 n-nearnest neighbors셋 $S_i$를 생성한다.
단, k개의 neighbors는 모두 소수클래스에 속한 관측치이다. 그러면 새로운 합성 관측치 $x_{syn}$은
[ x_{syn} = x_i + λ (x_k-x_i), x_k \in S_i ]
$\mathbf{x_i}$는 $S_i$에서 임의로 추출, λ는 0~1의 값으로 균등분포에서 임의로 추출한다 - 이러한 절차를 소수클래스에 속한 모든 관측치에 대해 다수클래스에 속하는 수가 될때까지 반복적으로 실시한다.
2) ADASYN
Adaptive Synthetic Sampling Method, 조절합성표집법
- ADASYN은 SMOTE와 동일하지만, 소수클래스에 있는 각 $x_i$에 대응하여 생성된 합성표본수를 $S_i$안에 포함된 다수클래스의 표본 수에 비례하도록 추출한 것만 차이가 있다. 여기에서 다수클래스는 해당 소수클래스에 속하지 않은 클래스를 의미한다.
Reference
- 박유성,『파이썬을 이용한 통계적 머신러닝』, 자유아카데미(2020)
- https://datascienceschool.net/view-notebook/c1a8dad913f74811ae8eef5d3bedc0c3/
- https://mkjjo.github.io/python/2019/01/04/smote_duplicate.html
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE, ADASYN
make_classification함수는 설정에 따른 분류용 가상 데이터를 생성하는 명령이다. 이 함수의 인수와 반환값은 다음과 같다.
인수:
- n_samples : 표본 데이터의 수, 디폴트 100
- n_features : 독립 변수의 수, 디폴트 20
- n_informative : 독립 변수 중 종속 변수와 상관 관계가 있는 성분의 수, 디폴트 2
- n_redundant : 독립 변수 중 다른 독립 변수의 선형 조합으로 나타나는 성분의 수, 디폴트 2
- n_repeated : 독립 변수 중 단순 중복된 성분의 수, 디폴트 0
- n_classes : 종속 변수의 클래스 수, 디폴트 2
- n_clusters_per_class : 클래스 당 클러스터의 수, 디폴트 2
- weights : 각 클래스에 할당된 표본 수
- random_state : 난수 발생 시드